Replication Logique Fonctionnement Interne
Table des matières
Introduction
J’ai présenté la réplication à travers plusieurs articles :
- PostgreSQL 10 et la réplication logique - Fonctionnement
- PostgreSQL 10 et la réplication logique - Mise en oeuvre
- PostgreSQL 10 et la réplication logique - Restrictions
Cet article va creuser un peu plus le sujet. Nous verrons plus en détail son fonctionnement. Pour mieux l’appréhender, j’ai rajouté des graphes dans Netdata que j’ai présenté dans un précédent article. Je vous invite à cliquer sur les images pour les agrandir, elles seront plus lisibles 😄
Je remercie au passage Guillaume Lelarge qui a joué le rôle de relecteur pour cet article.
Sérialisation des changements sur disque
J’ai remarqué que lors d’une grosse transaction, des fichiers apparaissaient dans le répertoire pg_replslot de chaque slot de réplication. C’est ce qui m’a poussé à chercher à comprendre à quoi servaient ces fichiers.
PostgreSQL doit réordonner les modifications pour qu’elles soient appliquées dans le bon ordre. Pour ce faire, les processus wal sender procèdent au décodage logique et réordonnent les changements en mémoire.
Cependant, si la transaction comprend beaucoup de changements, cela consommerait beaucoup de mémoire. Ils écrivent donc ces changements sur disque.
Après une exploration dans le code, on arrive dans le fichier src/backend/replication/logical/reorderbuffer.c :
1 139 /*
2 140 * Maximum number of changes kept in memory, per transaction. After that,
3 141 * changes are spooled to disk.
4 142 *
5 143 * The current value should be sufficient to decode the entire transaction
6 144 * without hitting disk in OLTP workloads, while starting to spool to disk in
7 145 * other workloads reasonably fast.
8 146 *
9 147 * At some point in the future it probably makes sense to have a more elaborate
10 148 * resource management here, but it's not entirely clear what that would look
11 149 * like.
12 150 */
13 151 static const Size max_changes_in_memory = 4096;
À partir de 4096 modifications, le moteur écrit les changements sur disque :
12048 /*
22049 * Check whether the transaction tx should spill its data to disk.
32050 */
42051 static void
52052 ReorderBufferCheckSerializeTXN(ReorderBuffer *rb, ReorderBufferTXN *txn)
62053 {
72054 /*
82055 * TODO: improve accounting so we cheaply can take subtransactions into
92056 * account here.
102057 */
112058 if (txn->nentries_mem >= max_changes_in_memory)
12[...]
132065 /*
142066 * Spill data of a large transaction (and its subtransactions) to disk.
152067 */
162068 static void
172069 ReorderBufferSerializeTXN(ReorderBuffer *rb, ReorderBufferTXN *txn)
182070 {
192071 dlist_iter subtxn_i;
202072 dlist_mutable_iter change_i;
212073 int fd = -1;
222074 XLogSegNo curOpenSegNo = 0;
232075 Size spilled = 0;
242076 char path[MAXPGPATH];
252077
262078 elog(DEBUG2, "spill %u changes in XID %u to disk",
272079 (uint32) txn->nentries_mem, txn->xid);
En plaçant le paramètre log_min_messages sur debug2, on peut arriver à mettre
en évidence ce comportement. Le but est d’afficher le message correspondant à la
ligne 2078.
Sans activité particulière, voici le contenu du répertoire pg_replslot :
1ls pg_replslot/* -alh
2pg_replslot/mysub:
3total 4,0K
4drwx------ 2 postgres postgres 19 févr. 18 15:46 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 15:46 state
7
8pg_replslot/mysub3:
9total 4,0K
10drwx------ 2 postgres postgres 19 févr. 18 15:46 .
11drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
12-rw------- 1 postgres postgres 176 févr. 18 15:46 state
J’ai deux répertoires, correspondants à deux slots de réplication. En effet, j’ai créé une publication et deux instances ont souscrit à la même publication. Elles ont chacune leur slot de réplication : mysub et mysub3.
Cas avec une seule transaction
Ajoutons des lignes à une table appartenant à une publication.
1begin;
2BEGIN
3postgres=# select count(*) from t1;
4 count
5-------
6 0
7(1 ligne)
8
9postgres=# insert into t1 (select i, md5(i::text) from generate_series(1,1000) i);
10INSERT 0 1000
11postgres=# insert into t1 (select i, md5(i::text) from generate_series(1,1000) i);
12INSERT 0 1000
13postgres=# insert into t1 (select i, md5(i::text) from generate_series(1,1000) i);
14INSERT 0 1000
15postgres=# insert into t1 (select i, md5(i::text) from generate_series(1,1000) i);
16INSERT 0 1000
17postgres=# insert into t1 (select i, md5(i::text) from generate_series(1,95) i);
18INSERT 0 95
19select count(*) from t1;
20 count
21-------
22 4095
23(1 ligne)
Jusqu’ici, nous n’avons pas atteint le seuil de 4096. Le répertoire ne contient encore que le fichier state :
1ls pg_replslot/* -alh
2pg_replslot/mysub:
3total 4,0K
4drwx------ 2 postgres postgres 19 févr. 18 15:52 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 15:52 state
7
8pg_replslot/mysub3:
9total 4,0K
10drwx------ 2 postgres postgres 19 févr. 18 15:52 .
11drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
12-rw------- 1 postgres postgres 176 févr. 18 15:52 state
Rajoutons une ligne :
1insert into t1 (select i, md5(i::text) from generate_series(1,1) i);
2INSERT 0 1
3postgres=# select count(*) from t1;
4 count
5-------
6 4096
7(1 ligne)
Cette fois, le seuil est atteint (if (txn->nentries_mem >= max_changes_in_memory).
Les processus wal sender vont écrire sur disque les changements à appliquer.
On retrouve dans les logs ces messages (avec log_min_messages = debug2) :
1[1977] postgres@postgres DEBUG: spill 4096 changes in XID 51689068 to disk
2[2061] postgres@postgres DEBUG: spill 4096 changes in XID 51689068 to disk
Correspondant aux deux processus wal sender :
1ps faux |grep -E '(1977|2061)'
2postgres 1977 3.3 0.3 390496 37984 ? Ss 11:38 8:54 \_ postgres: 10/main: wal sender process postgres 192.168.1.26(44188) idle
3postgres 2061 3.4 0.3 390496 37932 ? Ss 11:38 9:10 \_ postgres: 10/main: wal sender process postgres 192.168.1.26(44192) idle
Dans le même temps, si on regarde le contenu du répertoire pg_replslot, on remarque que de nouveaux fichiers sont apparus :
1ls pg_replslot/* -alh
2pg_replslot/mysub:
3total 660K
4drwx------ 2 postgres postgres 60 févr. 18 15:53 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 15:53 state
7-rw------- 1 postgres postgres 656K févr. 18 15:53 xid-51689068-lsn-92-98000000.snap
8
9pg_replslot/mysub3:
10total 660K
11drwx------ 2 postgres postgres 60 févr. 18 15:53 .
12drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
13-rw------- 1 postgres postgres 176 févr. 18 15:53 state
14-rw------- 1 postgres postgres 656K févr. 18 15:53 xid-51689068-lsn-92-98000000.snap
Chaque wal sender a dû sérialiser les changements sur disque.
On remarque également que la notion de changement correspond à une ligne et non un ordre. Par exemple, un seul insert de 4096 lignes entrainera l’écriture d’un fichier *.snap.
Edit : Les développeurs de Postgres ont changé l’extension snap pour spill pour Postgres 12 :
1commit ba9d35b8eb8466cf445c732a2e15ca5790cbc6c6
2Author: Jeff Davis <jdavis@postgresql.org>
3AuthorDate: Sat Aug 25 22:45:59 2018 -0700
4Commit: Jeff Davis <jdavis@postgresql.org>
5CommitDate: Sat Aug 25 22:52:46 2018 -0700
6
7 Reconsider new file extension in commit 91f26d5f.
8
9 Andres and Tom objected to the choice of the ".tmp"
10 extension. Changing to Andres's suggestion of ".spill".
11
12 Discussion: https://postgr.es/m/88092095-3348-49D8-8746-EB574B1D30EA%40anarazel.de
Cas avec deux transactions
Deuxième exemple, avec deux transactions modifiant la table t1.
Le xid de la première transaction :
1select txid_current();
2 txid_current
3--------------
4 51689070
5(1 ligne)
Celui de la seconde transaction :
1select txid_current();
2 txid_current
3--------------
4 51689071
5(1 ligne)
Si on insère 4096 lignes dans la première transaction :
1ls pg_replslot/* -alh
2pg_replslot/mysub:
3total 660K
4drwx------ 2 postgres postgres 60 févr. 18 16:08 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 16:08 state
7-rw------- 1 postgres postgres 656K févr. 18 16:07 xid-51689070-lsn-92-98000000.snap
8
9pg_replslot/mysub3:
10total 660K
11drwx------ 2 postgres postgres 60 févr. 18 16:08 .
12drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
13-rw------- 1 postgres postgres 176 févr. 18 16:08 state
14-rw------- 1 postgres postgres 656K févr. 18 16:07 xid-51689070-lsn-92-98000000.snap
Ensuite, si on insère 4096 lignes dans la seconde transaction, nous obtenons deux nouveaux fichiers *.snap :
1ls pg_replslot/* -alh
2pg_replslot/mysub:
3total 1,3M
4drwx------ 2 postgres postgres 101 févr. 18 16:08 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 16:08 state
7-rw------- 1 postgres postgres 656K févr. 18 16:07 xid-51689070-lsn-92-98000000.snap
8-rw------- 1 postgres postgres 656K févr. 18 16:08 xid-51689071-lsn-92-98000000.snap
9
10pg_replslot/mysub3:
11total 1,3M
12drwx------ 2 postgres postgres 101 févr. 18 16:08 .
13drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
14-rw------- 1 postgres postgres 176 févr. 18 16:08 state
15-rw------- 1 postgres postgres 656K févr. 18 16:07 xid-51689070-lsn-92-98000000.snap
16-rw------- 1 postgres postgres 656K févr. 18 16:08 xid-51689071-lsn-92-98000000.snap
J’ai essayé en insérant 3000 lignes dans chaque transaction, aucun fichier snap n’est écrit. Ce n’est que lorsque chaque transaction dépasse 4096 changements que ceux-ci sont écrits sur disque.
Commitons la première transaction :
1ls pg_replslot/* -alh
2pg_replslot/mysub:
3total 660K
4drwx------ 2 postgres postgres 60 févr. 18 16:15 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 16:15 state
7-rw------- 1 postgres postgres 656K févr. 18 16:08 xid-51689071-lsn-92-98000000.snap
8
9pg_replslot/mysub3:
10total 660K
11drwx------ 2 postgres postgres 60 févr. 18 16:15 .
12drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
13-rw------- 1 postgres postgres 176 févr. 18 16:15 state
14-rw------- 1 postgres postgres 656K févr. 18 16:08 xid-51689071-lsn-92-98000000.snap
Le fichier snap correspondant est supprimé par chaque wal sender. Si on commite la deuxième transaction, le second fichier est également supprimé.
Il est à noter que ces fichiers apparaissent pour toute modification (DELETE, UPDATE…).
Que se passe t’il pour une grosse transaction?
Dans cet exemple, nous allons insérer une grande quantité d’enregistrements dans une transaction qui sera commitée plus tard, afin de mettre en évidence le fonctionnement de la réplication logique.
Voici les requêtes qui ont été exécutées :
1BEGIN.
2INSERT INTO t1 (select i, md5(i::text) FROM generate_series(1,10000000) i); --16h27min13s
3-- attente de plusieurs minutes
4COMMIT; --16h33min46s
Pour information, la requête d’insertion a été lancée peu après 16h27min13s et s’est terminée à 16h28min16s.
Le commit n’a été fait que bien plus tard, à 16h33min46s.
Nous constatons que les deux processus wal sender vont sérialiser les changements sur disque :
1[1977] postgres@postgres DEBUG: spill 4096 changes in XID 51689075 to disk
2[2061] postgres@postgres DEBUG: spill 4096 changes in XID 51689075 to disk
3[1977] postgres@postgres DEBUG: spill 4096 changes in XID 51689075 to disk
4[2061] postgres@postgres DEBUG: spill 4096 changes in XID 51689075 to disk
5[1977] postgres@postgres DEBUG: spill 4096 changes in XID 51689075 to disk
6[2061] postgres@postgres DEBUG: spill 4096 changes in XID 51689075 to disk
Ce qui produit une grosse quantité de fichiers :
1[...]
2pg_replslot/mysub3:
3total 1,6G
4drwx------ 2 postgres postgres 8,0K févr. 18 16:28 .
5drwx------ 4 postgres postgres 33 févr. 18 11:51 ..
6-rw------- 1 postgres postgres 176 févr. 18 16:28 state
7-rw------- 1 postgres postgres 1,1M févr. 18 16:27 xid-51689075-lsn-92-98000000.snap
8-rw------- 1 postgres postgres 15M févr. 18 16:27 xid-51689075-lsn-92-99000000.snap
9-rw------- 1 postgres postgres 16M févr. 18 16:27 xid-51689075-lsn-92-9A000000.snap
10-rw------- 1 postgres postgres 16M févr. 18 16:27 xid-51689075-lsn-92-9B000000.snap
11-rw------- 1 postgres postgres 16M févr. 18 16:27 xid-51689075-lsn-92-9C000000.snap
12[...]
Voici quelques graphes issus de Netdata :
CPU
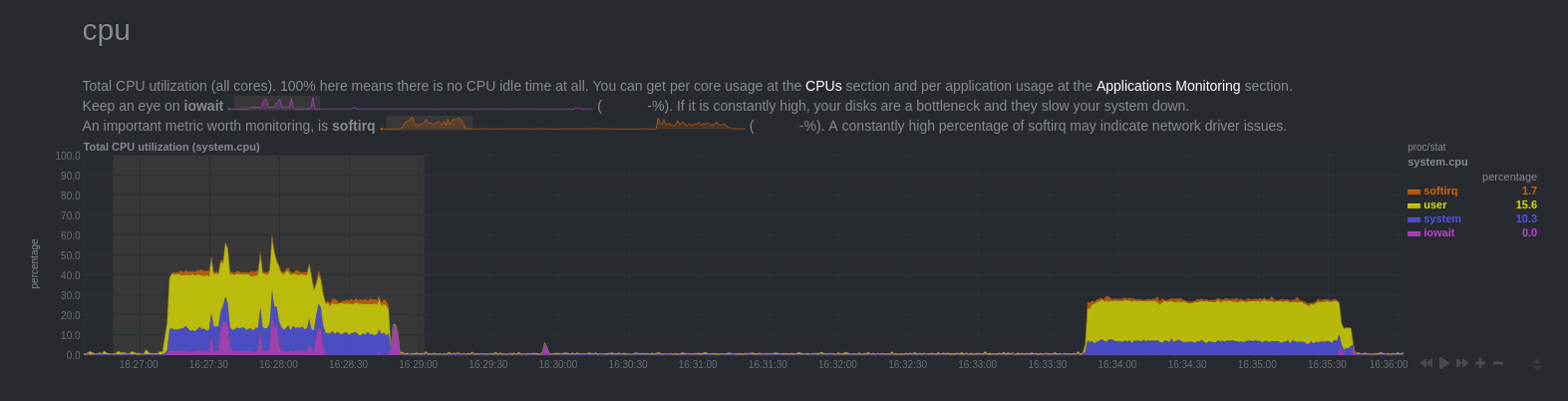
CPU
On constate une forte charge CPU, jusqu’à 16h28min16s où elle baisse un peu. Puis à 16h28min48s la charge redescend à 0. On retrouve une hausse de la charge à 16h33min46s.
Comment expliquer ces résultats?
Lors du premier pic de charge, il y avait plusieurs processus qui consommait de la ressource :
- le backend qui insérait les données
- les deux processus wal sender
La machine dispose de 8 coeurs logiques, chaque processus n’exploite qu’un seul coeur. Soit environ 13% par processus.
A 16h28min16s, le backend venait de terminer l’insertion. Cependant, les processus wal sender continuaient d’être actifs. Le décodage des journaux et la sérialisation des transactions sont assez coûteux.
Enfin, à 16h33min46s, la transaction est commitée. Ca n’a eu aucune incidence sur la charge du backend. En revanche, les processus wal sender se sont mis à lire les fichiers snap produits sur disque pour transmettre les modifications aux souscripteurs.
À noter que les changements n’ont été visibles côté souscripteur que vers 16h35min40s, une fois que les changements ont été rejoués. Le rejeu est plus long que l’insertion. Cela dépend beaucoup des performances des processeurs.
Statistiques sur les enregistrements

tuple inserted
On constate un pic d’insertion à 16h33min46s. Cela correspond bien au moment où la transaction a été commitée.
Réseau

Réseau
On constate un important trafic réseau entre 16h33min46s et 16h35min40s. On peut en déduire que les changements ne sont transmis qu’après le commit.
Les changements ne sont pas transmis “au fil de l’eau”. Cela présente l’avantage d’éviter d’envoyer des changements qui ne seraient pas commités. En revanche, cela rajoute du délai dans l’application des changements.
Thomas Vondra a soumis un patch afin d’améliorer ce cas d’usage : logical streaming for large in-progress transactions
Pour le moment le patch n’a pas encore été accepté. Il nécessite de rajouter des informations dans les journaux de transaction. La communauté est très prudente en ce qui concerne tout ce qui peut avoir un impact sur les performances.
Réplication
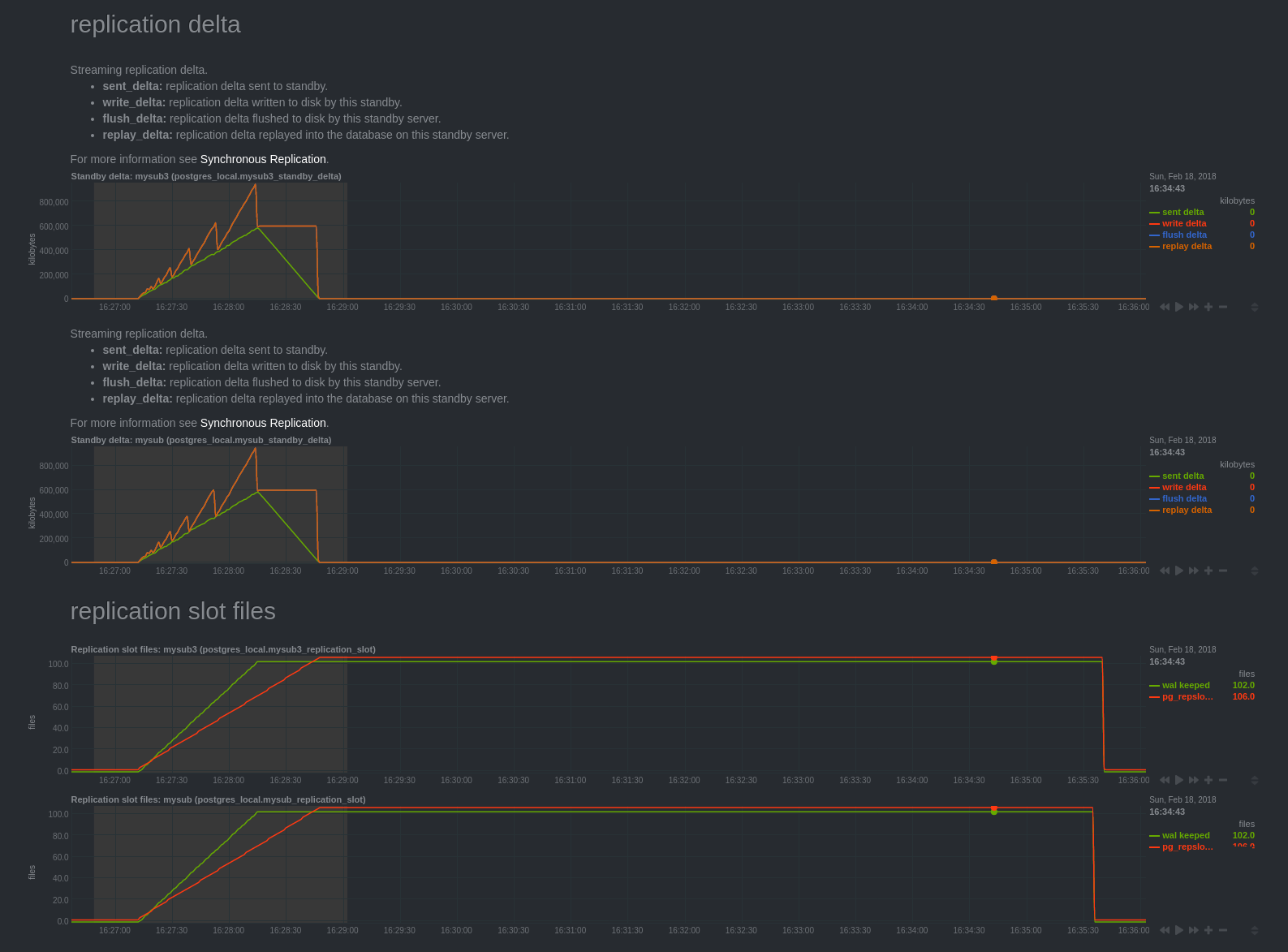
Réplication delta
On peut noter que les graphes “Streaming replication delta” mesurant le delta de
réplication à partir de la vue pg_stat_replication sont difficiles à expliquer.
Normalement, ils présentent le retard de réplication de serveurs secondaires. Or
nous venons de voir que l’application des changements ne se fait que lors du
commit, soit à 16h33min46s. Or les graphes semblent indiquer que les serveurs
secondaires avaient du retard jusqu’à 16h28min48s.
Les courbes “write delta”, “flush delta” et “replay delta” se confondent. La courbe “sent delta” est assez différente.
Ma compréhension de ces graphes est que “write delta”, “flush delta” et “replay delta” correspondent au retard de décodage logique par rapport aux données envoyées “sent delta”.
A 16h28min16s, la requête s’est terminée, le “sent delta” arrête de croître. Puis, décroit au fur et à mesure de l’avancée du décodage logique.
On peut confirmer cela grâce aux graphes “replication slot files”, la courbe “pg_replslot files” correspond au nombre de fichiers présents dans le répertoire “pg_replslot” de chaque slot de réplication. Celle-ci est croissante et s’arrête de croitre au même moment où les courbes “write delta”, “flush delta” et “replay delta” redescendent à 0.
On constate également que le moteur est contraint de conserver les journaux de transaction tant que la transaction n’a pas été commitée. C’est assez logique, si un crash survenait, il faudrait pouvoir aller lire les journaux de transaction pour procéder à nouveau au décodage logique.
Enfin, à 16h35min40s les changements ont bien été transmis côté souscripteur, le moteur peut enfin nettoyer les journaux de transaction et les fichiers snaps.
Trafic OLTP
Et avec un trafic OLTP? Pour ce test, j’ai utilisé pgbench lancé pendant 10 minutes sur une base dont toutes les tables sont répliquées.
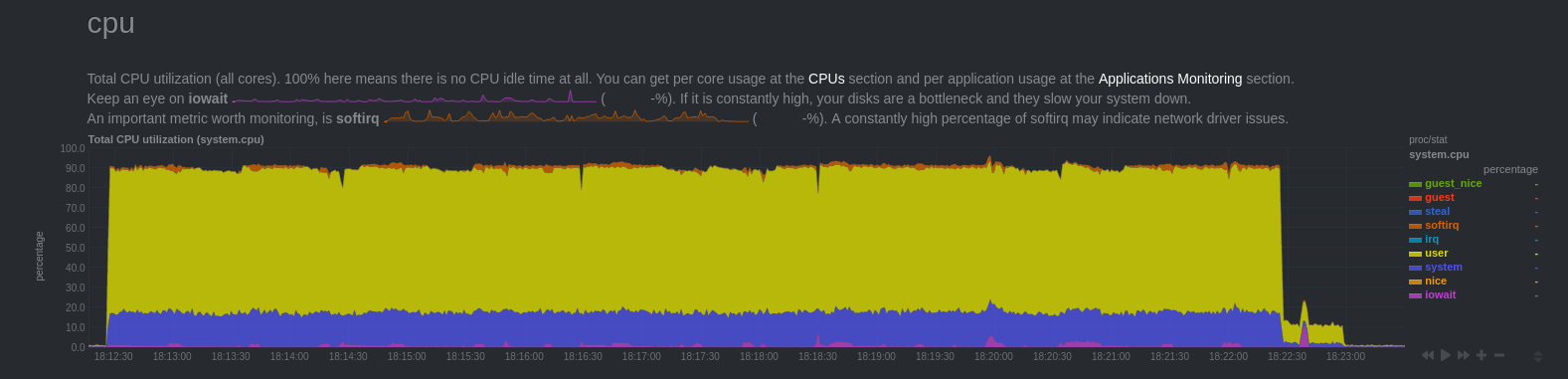
Charge CPU
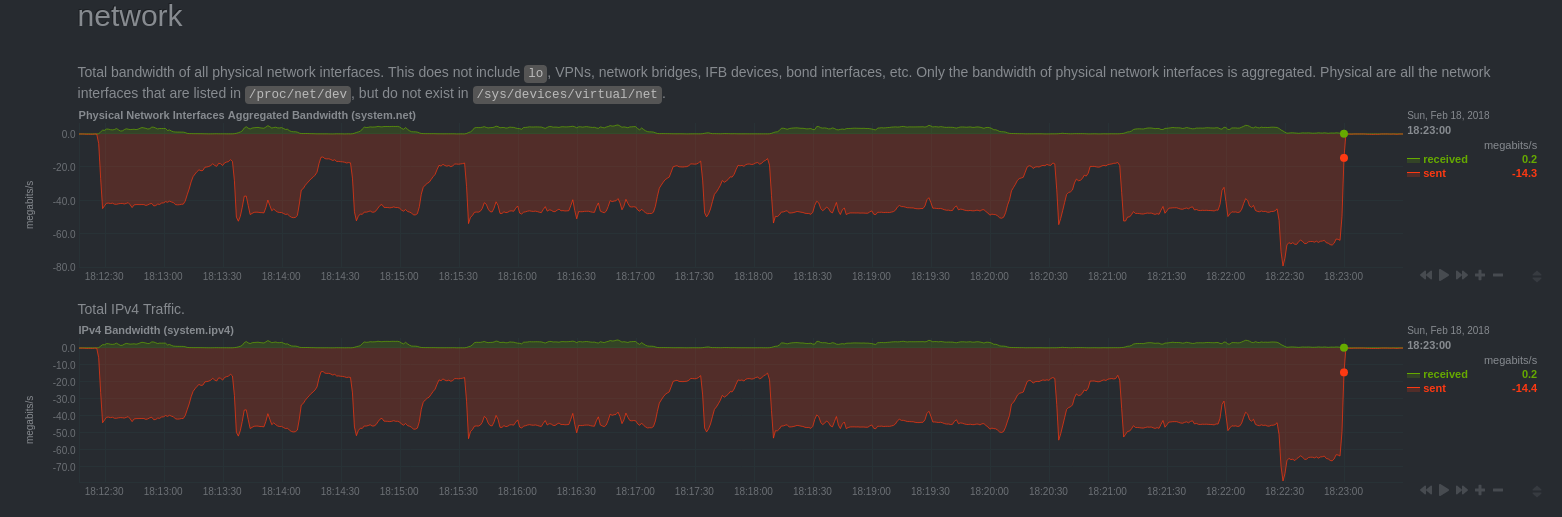
Activité réseau
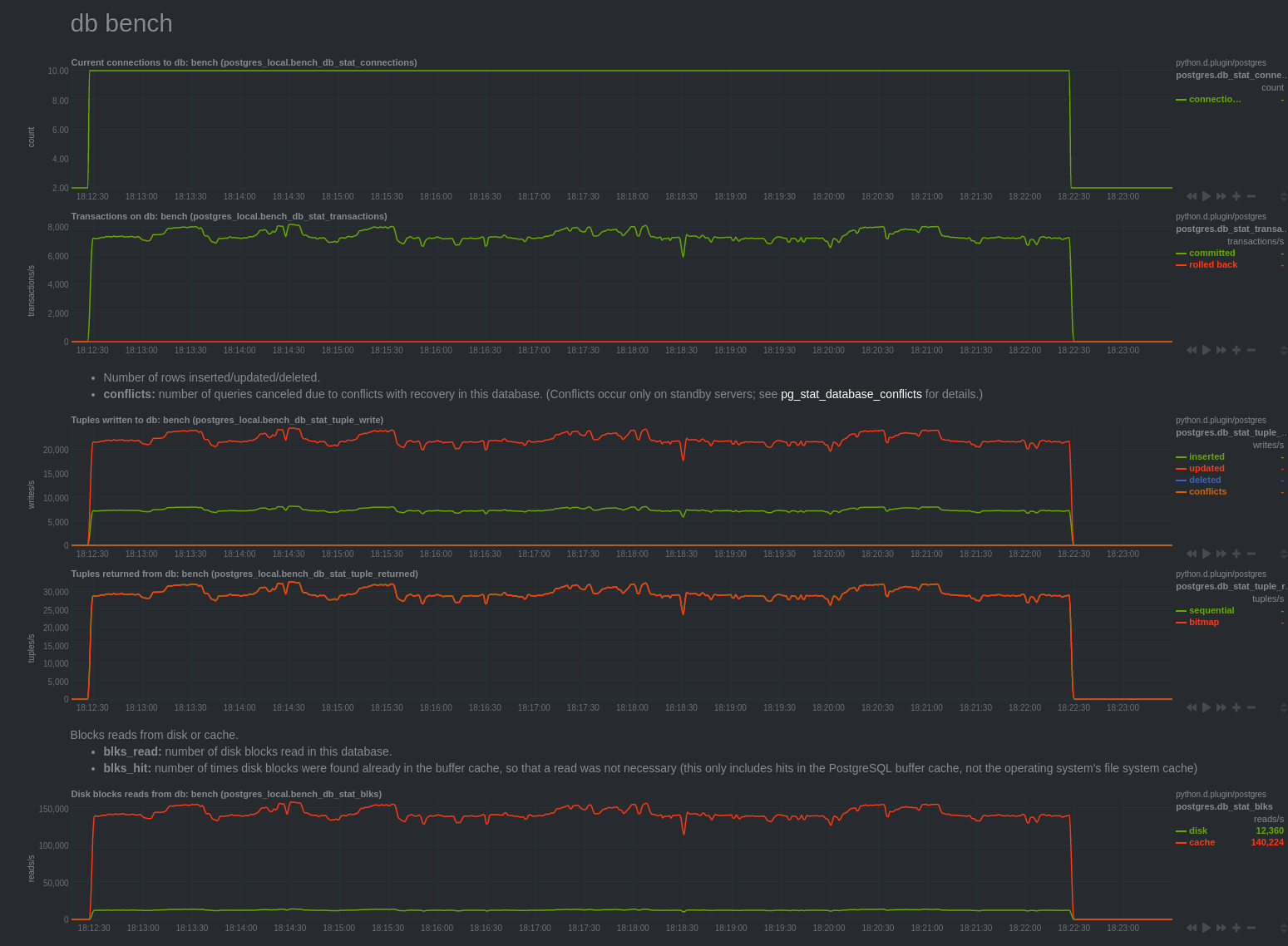
Activité transactions
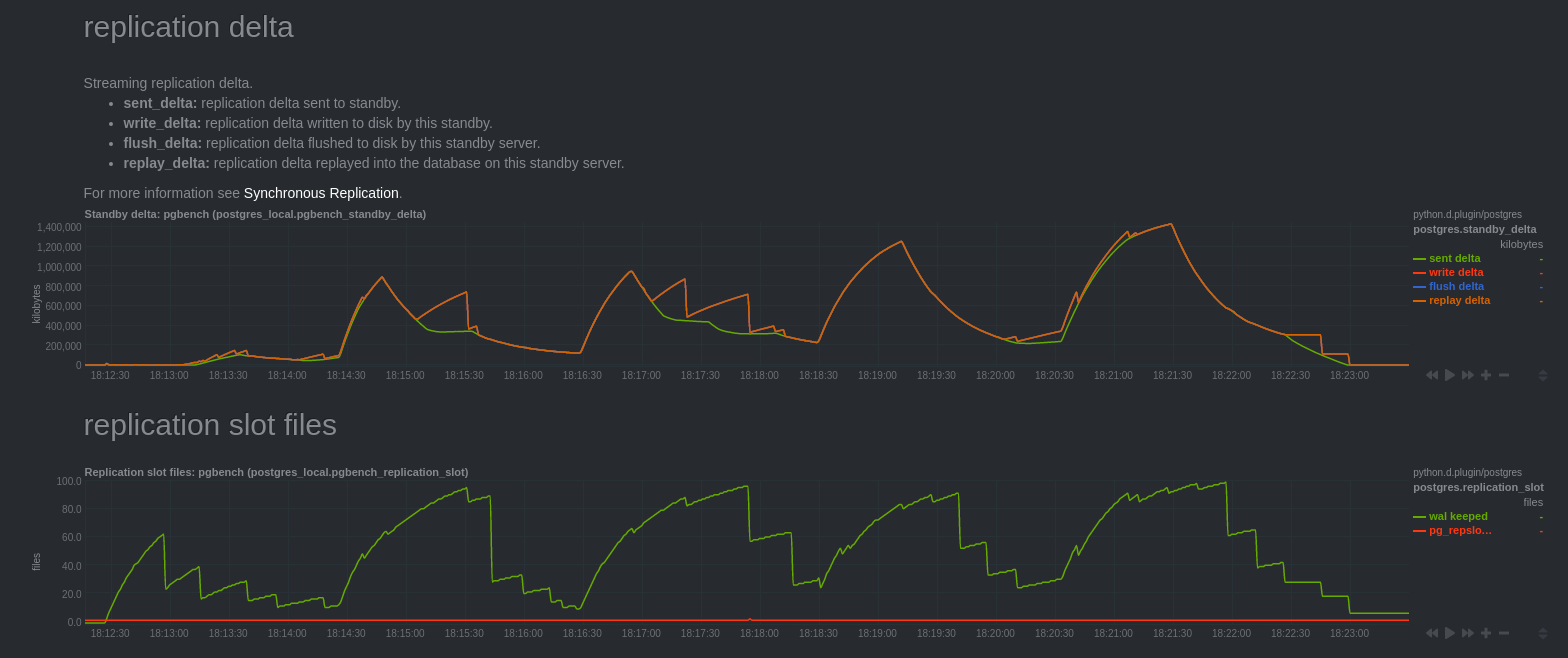
Réplication delta
On remarque que le trafic réseau chute au même moment que nous observons un retard de réplication qui augmente. Cela correspondait à des périodes où le secondaire saturait côté CPU (malheureusement je n’ai pas de graphe Netdata sur le secondaire).
Cela peut s’expliquer par le fait que le rejeu ne se fait que grâce à un seul processus bgworker qui avait du mal à supporter la charge (machine moins puissante). D’ailleurs, on peut voir que le secondaire rattrape le retard quelques dizaines de secondes après la fin du bench.
Autre point important, on constate qu’il n’y a aucun fichier snap écrit sur disque. Cela confirme le commentaire dans le code, indiquant qu’en cas de trafic OLTP, les changements sont conservés en mémoire et non sur disque.
Bilan
On peut constater que la réplication logique s’applique assez bien dans le cas d’un trafic OLTP pour peu que le secondaire arrive à suivre l’application des changements. Cela implique que le trafic en écriture ne peut être trop important au risque d’avoir un secondaire qui a du mal à encaisser la charge, l’application des changements s’effectuant par un seul processus.
En revanche, dans les cas où le trafic est différent (OLAP), où des requêtes entraînent des changements importants, le moteur devra sérialiser les changements sur disque. Les opérations de décodage logique, puis de transfert réseau induisent un délai qui peut être non négligeable.

J’ai occupé pendant 7 ans divers postes d’ingénieur système et réseau. Et c’est à partir de 2013 que j’ai commencé à mettre les doigts dans PostgreSQL. J’ai occupé des postes de consultant, formateur, mais également DBA de production (Doctolib, Peopledoc).
Ce blog me permet de partager mes connaissances et trouvailles, ainsi que mes interventions et conférences.