PostgreSQL 10 et la réplication logique – Fonctionnement
Certains d’entre vous sont déjà au courant, la nouvelle version majeure de PostgreSQL approche à grands pas. Elle devrait sortir dans le courant du mois de septembre.
Comme chaque nouvelle version la liste de nouveautés est assez impressionnante :
- partitionnement
- amélioration des performances sur les tris et fonctions d’agrégation
- extension du parallélisme : parcours d’index parallélisé, jointure parallélisée, parallélisation des sous-requêtes…
- statistiques étendues
- support des collations ICU : va permettre d’exploiter les « abbreviated keys » qui avaient dû être désactivées en 9.5 à cause d’un bug dans la libc. Les « abbreviated keys » permettaient un gain de l’ordre de 20-30% sur les tris et créations d’index.
- et je m’arrête là, vous pouvez avoir un aperçu des nouveautés sur la page wiki ou dans les releases notes.
Une grande nouveauté de la version 10 que je vais présenter dans une série d’articles est la réplication logique.
- PostgreSQL 10 et la réplication logique - Fonctionnement
- PostgreSQL 10 et la réplication logique - Mise en oeuvre
- PostgreSQL 10 et la réplication logique - Restrictions
Rappel
La réplication existe déjà dans PostgreSQL 1. Elle reposait sur la réplication dite « physique » : le moteur ne réplique pas des requêtes mais le résultat de la requête. Plus précisément les modifications des blocs de données.
Le serveur secondaire se contente de rejouer les journaux de transaction. Cette technique est assez simple et est particulièrement efficace et fiable.
Néanmoins elle présente quelques limitations :
- il n’existe aucune granularité, on est obligé de répliquer l’intégralité de l’instance
- il n’est pas possible de faire une réplication entre différentes architecture (x86, ARM…).
- le secondaire n’accepte aucune requête en écriture. Il n’est dont pas possible de créer des vues personnalisées ou des index.
Fonctionnement
Contrairement à la réplication physique, la réplication logique ne réplique pas les blocs de données. Elle décode le résultat des requêtes qui est transmis au secondaire. Celui-ci applique les modifications SQL issues du flux de réplication logique.
Le serveur secondaire est en réalité un serveur primaire, dans le sens où il s’agît d’un serveur qui accepte des requêtes en écritures comme n’importe quel instance primaire.
Il sera ainsi possible de choisir les tables à répliquer, de rajouter des vues et index sur le serveur secondaire etc…
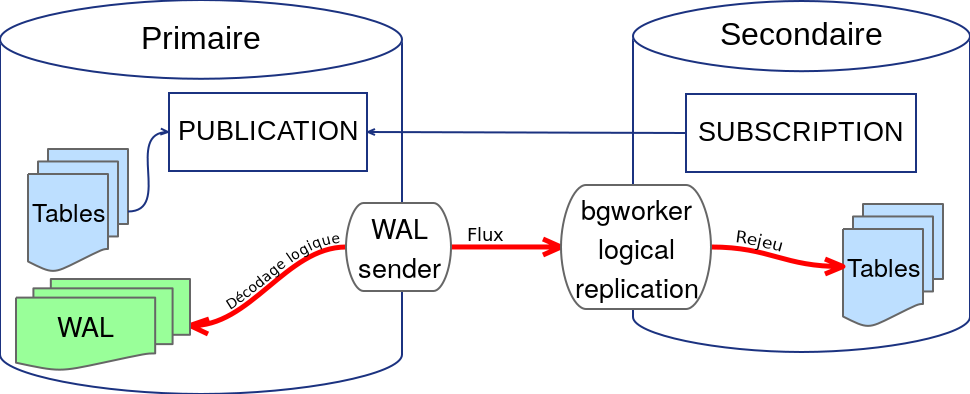
Schéma réplication logique
- Une « publication » est créée sur le serveur primaire (« publieur »), celle-ci comprend les tables appartenant à la publication.
- Le secondaire souscrit à cette publication, c’est un « souscripteur ».
- Ensuite un processus spécial est lancé : le « bgworker logical replication ». Il va se connecter à un slot de réplication sur le serveur primaire.
- Le serveur primaire va procéder à un décodage logique des journaux de transaction pour extraire les résultats des ordres SQL.
- Le flux logique est transmis au secondaire qui les applique sur les tables.
La mise en oeuvre dans un prochain article…
-
Par transfert de journaux de transaction depuis la version 8.2 sortie en 2006 et en flux depuis la version 9.0 sortie en 2010. ↩︎

J’ai occupé pendant 7 ans divers postes d’ingénieur système et réseau. Et c’est à partir de 2013 que j’ai commencé à mettre les doigts dans PostgreSQL. J’ai occupé des postes de consultant, formateur, mais également DBA de production (Doctolib, Peopledoc).
Ce blog me permet de partager mes connaissances et trouvailles, ainsi que mes interventions et conférences.