Index BRIN – Performances
La version 9.5 de PostgreSQL sortie en Janvier 2016 propose un nouveau type d’index : les Index BRIN pour Bloc Range INdex. Ces derniers sont recommandés pour les tables volumineuses et corrélées avec leur emplacement. J’ai décidé de consacrer une série d’article sur ces index :
- Index BRIN - Principe
- Index BRIN - Fonctionnement
- Index BRIN - Corrélation
- Index BRIN - Performances
Pour information, je serai présent au PGDay France à Lille le mardi 31 mai pour présenter cet index. Il y aura également plein d’autres conférences intéressantes!
Cet article est la dernier de la série, il sera consacré aux performances (maintenance, lecture, insertion…)
Performances
Les articles précédents ont abordé le fonctionnement et les spécificités des index BRIN. Cet article sera plutôt consacré aux performances. Les exemples précédents portaient sur de petites volumétries. Maintenant nous allons voir ce que peuvent apporter ces index sur une volumétrie plus importante.
Les tests ont été effectués sur un PC portable, les journaux de transaction, la table et les index sont stockés sur un disque mécanique. Les résultats seront différents suivant la matériel utilisé. Ces chiffres sont purement indicatifs et servent surtout à se donner un ordre d’idée.
Exemple
Dans un premier temps il est nécessaire de créer une table avec une volumétrie importante.
Par exemple : un système de mesure avec 100 sondes et une mesure toutes les secondes. Nous allons donc obtenir 100*365*24*3600 mesures => un peu plus de 3 milliards de lignes.
1-- Utilisation d'une fonction pour générer du texte aléatoire.
2-- Trouvée ici : http://stackoverflow.com/questions/3970795/how-do-you-create-a-random-string-in-postgresql
3
4CREATE OR REPLACE FUNCTION random_string(LENGTH INTEGER) RETURNS text AS
5$$
6DECLARE
7 chars text[] := '{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z}';
8 RESULT text := '';
9 i INTEGER := 0;
10BEGIN
11 IF LENGTH < 0 THEN
12 raise exception 'Given length cannot be less than 0';
13 END IF;
14 FOR i IN 1..LENGTH loop
15 RESULT := RESULT || chars[1+random()*(array_length(chars, 1)-1)];
16 END loop;
17 RETURN RESULT;
18END;
19$$ LANGUAGE plpgsql;
20-- Creation de la table contenant les sondes
21CREATE TABLE probe (id serial PRIMARY KEY, name text);
22INSERT INTO probe (name ) SELECT random_string(5) FROM generate_series(1,100);
23
24CREATE TABLE data AS
25WITH generation AS (
26SELECT '2015-01-01'::TIMESTAMP + i * INTERVAL '1 second' AS date_metric,sonde::text,random() AS metric
27FROM generate_series(0, 3600*24*365) i,
28LATERAL (SELECT name FROM probe) sonde)
29SELECT * FROM generation;
La table obtenue fait un peu plus de 150Go, elle ne rentre donc pas dans la RAM de la machine hébergeant l’instance et encore moins dans la mémoire partagée de PostgreSQL.
Maintenance
On crée plein d’index pour comparer leur taille :
1CREATE INDEX metro_btree_idx ON data USING btree (date_metric);
2CREATE INDEX metro_brin_idx_8 ON data USING brin (date_metric) WITH (pages_per_range = 8);
3CREATE INDEX metro_brin_idx_16 ON data USING brin (date_metric) WITH (pages_per_range = 16);
4CREATE INDEX metro_brin_idx_32 ON data USING brin (date_metric) WITH (pages_per_range = 32);
5CREATE INDEX metro_brin_idx_64 ON data USING brin (date_metric) WITH (pages_per_range = 64);
6CREATE INDEX metro_brin_idx_128 ON data USING brin (date_metric);
7CREATE INDEX metro_brin_idx_256 ON data USING brin (date_metric) WITH (pages_per_range = 256);
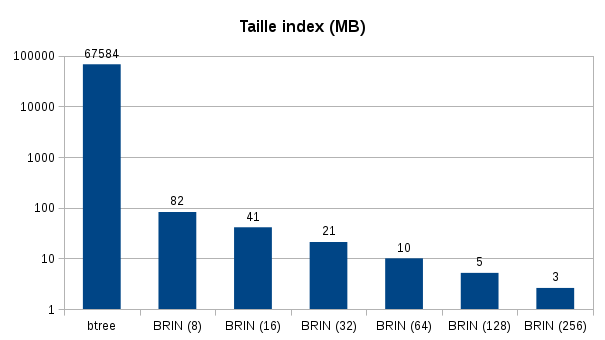
Voici les résultats obtenus pour la durée de création des index et leurs tailles :
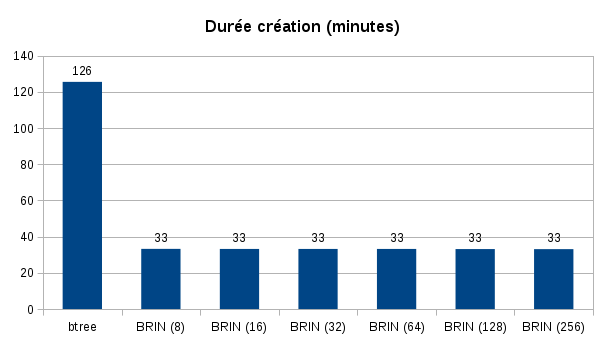
La création de l’index a été 4 fois plus rapide pour les index BRIN. Il est possible que leur création aurait été plus rapide avec un stockage plus performant.
La taille des index est également frappante, l’index b-tree fait 66 Go alors que l’index BRIN avec le pages_per_range par défaut fait seulement 5 Mo.
On peut tout suite constater le gain sur l’espace utilisé et la rapidité de création des index. Les opérations de maintenances (REINDEX) seront grandement facilitées.
Performances en lecture
Nous allons effectuer plusieurs tests, l’idée est d’essayer de mettre en valeur les différences de comportements entre les index BRIN et b-tree.
La requête utilisée sera tout simple :
1EXPLAIN (ANALYSE,BUFFERS,VERBOSE) SELECT date_metric,sonde,metric FROM DATA WHERE date_metric = 'xxx';
Pour obtenir un résultat avec peu de lignes :
1WHERE date_metric = '2015-05-01 00:00:00'::TIMESTAMP
Pour obtenir plus de résultat on prendra un intervalle avec :
1WHERE date_metric BETWEEN 'xxx'::TIMESTAMP AND 'xxx'::TIMESTAMP;
Voici les résultats obtenus :
| lignes |
|---|
| Durée |
| 100 |
| 267 millions |
| 777 millions |
| 1.3 milliard |
Pour comparer le volume de données lues et la durée d’exécution nous pouvons désactiver les index dans une transaction :
1BEGIN;
2DROP index ...;
3explain (analyse,verbose,buffers) SELECT ...
4rollback;
Pour le 1er test, le moteur choisit l’index-btree. En supprimant l’index b-tree il choisit l’index BRIN.
Pour les tests 2 et 3, le moteur choisit l’index BRIN, en supprimant l’index BRIN il choisit l’index b-tree.
Pour le dernier test j’ai rajouté d’autres mesures. En effet, en supprimant l’index BRIN le moteur va effectuer un seqscan (parcours de toute la table). Pour obtenir les mêmes comparaisons que les résultats précédents j’ai donc supprimé l’index BRIN et désactivé les parcours séquentiels (set enable_seqscan to 'off';)
Globalement on peut constater un gain de 30-40% dans les cas où beaucoup de résultats sont demandés. Le moteur lit moins de blocs lorsqu’il utilise les index BRIN, l’index b-tree étant volumineux, ses lectures sont coûteuses.
En revanche l’index b-tree s’avère particulièrement performant lorsque la requête est très sélective et que peu de résultats sont retournés. En effet, en utilisant un index BRIN, le moteur commence par lire l’intégralité de l’index. Puis il va lire un ensemble de blocs qui contiennent la valeur recherchée, certains ne contenants aucun résultat. Ces lectures supplémentaires se ressentent sur la durée d’exécution de la requête.
Performances en insertion
Vu que les index BRIN sont plus petits et leur durée de création plus courte, on peut se demander ce qu’il advient du surcoût de cet index lors d’insertion de données. Pour cela on va créer une table et mesurer l’insertion de 10 millions de lignes en fonction des index déjà présents sur la table. Afin de cibler le surcoût dû à la mise à jour des index, la table est non-journalisée, ceci permet d’éviter les écritures dans les journaux de transaction. L’autovacuum est également désactivé.
1CREATE UNLOGGED TABLE brin_demo_2 (c1 INT);
2INSERT INTO brin_demo_2 SELECT * FROM generate_series(1,10000000);
3TRUNCATE brin_demo_2;
4
5CREATE INDEX brin_demo_2_brin_idx ON brin_demo_2 USING brin (c1);
6INSERT INTO brin_demo_2 SELECT * FROM generate_series(1,10000000);
7DROP INDEX brin_demo_2_brin_idx;
8TRUNCATE brin_demo_2;
9
10CREATE INDEX brin_demo_2_brin_idx ON brin_demo_2 USING brin (c1) WITH (pages_per_range = 256);
11INSERT INTO brin_demo_2 SELECT * FROM generate_series(1,10000000);
12DROP INDEX brin_demo_2_brin_idx;
13TRUNCATE brin_demo_2;
14...
Voici les résultats obtenus :
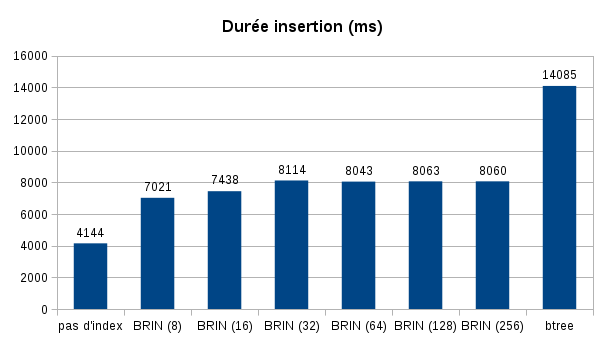
Cependant on peut constater qu’il est moins coûteux d’insérer des données dans une table avec un index BRIN qu’avec un index b-tree. On constate également qu’il n’y a pas d’écart significatif entre les différents types d’index BRIN.
Conclusion
Cette série d’articles a permis de présenter les principes des index BRIN. puis leur fonctionnement à travers des exemples simples.
Ensuite nous avons vu l’importance de la corrélation pour exploiter pleinement ces index. Enfin, nous avons essayé de mesurer le gain que pouvait apporter cet index sur de multiples aspect (maintenance, performance en lecture et insertion).
Décrire le fonctionnement d’un index en simplifiant sa représentation est un exercice compliqué. On peut vite sacrifier le fond à la forme. Présenter des chiffres est également délicat tellement ils peuvent dépendre du contexte. J’ai fait l’effort de détailler comment je les ai obtenu afin que chacun puisse reproduire ses propres tests. L’idée est de donner un aperçu des cas d’utilisation de ce type d’index.
Globalement il faut retenir que les index BRIN sont utiles pour les tables volumineuses et où la corrélation avec l’emplacement des données est importante. Ils seront plus lents que les index b-tree lorsque la recherche nécessite de parcourir peu de blocs. Ils seront un peu plus rapide que les index b-tree dans les situations où le moteur doit lire beaucoup de blocs (moins de blocs à lire dans l’index).
L’étude de cet index ouvre d’autres pistes de réflexion. Comme la prise en compte de la corrélation dans le calcul du coût. J’avais également pensé à la possibilité d’utiliser un index pour créer un autre index.
Dans l’exemple avec la table volumineuse (150Go). Si on souhaite créer un index partiel sur le mois précédent, le moteur va parcourir l’intégralité de la table pour créer d’index. On pourrait envisager créer l’index b-tree en utilisant l’index BRIN pour ne parcourir que les lignes correspondant au moins précédent.

J’ai occupé pendant 7 ans divers postes d’ingénieur système et réseau. Et c’est à partir de 2013 que j’ai commencé à mettre les doigts dans PostgreSQL. J’ai occupé des postes de consultant, formateur, mais également DBA de production (Doctolib, Peopledoc).
Ce blog me permet de partager mes connaissances et trouvailles, ainsi que mes interventions et conférences.