Introduction à Postgres – Part1
Cet article a pour but de présenter quelques principes de Postgres. Il n’est pas exhaustif, néanmoins si vous souhaitez approfondir j’ai agrémenté l’article de quelques liens que j’ai trouvé pertinents. Pour ceux qui veulent vraiment creuser je vous recommande la lecture des ouvrages de Greg Smith et les articles de Dalibo parus dans Linux Mag.
Quelques rappels sur Postgres. PostgreSQL est un moteur de base de données relationnel. Il respecte les propriétés ACID et la gestion MVCC des données. Juste un petit mot sur MVCC, Multiversion Concurrency Control est un mécanisme très puissant de Postgres. Je ne rentrerai pas dans les détails mais ce mécanisme permet entre autre les accès concurrents à une base de donnée.
Plutôt que de réinventer la roue voici les articles de Wikipédia qui abordent ACID et MVCC :
Propriétés ACID
Atomicité
La propriété d’atomicité assure qu’une transaction se fait au complet ou pas du tout : si une partie d’une transaction ne peut être faite, il faut effacer toute trace de la transaction et remettre les données dans l’état où elles étaient avant la transaction. L’atomicité doit être respectée dans toutes situations, comme une panne d’électricité, une défaillance de l’ordinateur, ou une panne d’un disque magnétique.
Cohérence
La propriété de cohérence assure que chaque transaction amènera le système d’un état valide à un autre état valide. Tout changement à la base de données doit être valide selon toutes les règles définies, incluant mais non limitées aux contraintes d’intégrité, aux rollbacks en cascade, aux déclencheurs de base de données, et à toutes combinaisons d’évènements.
Isolation
La propriété d’isolation assure que l’exécution simultanée de transactions produit le même état que celui qui serait obtenu par l’exécution en série des transactions. Chaque transaction doit s’exécuter en isolation totale : si T1 et T2 s’exécutent simultanément, alors chacune doit demeurer indépendante de l’autre.
Durabilité
La propriété de durabilité assure que lorsqu’une transaction a été confirmée, elle demeure enregistrée même à la suite d’une panne d’électricité, d’une panne de l’ordinateur ou d’un autre problème. Par exemple, dans une base de données relationnelle, lorsqu’un groupe d’énoncés SQL ont été exécutés, les résultats doivent être enregistrés de façon permanente, même dans le cas d’une panne immédiatement après l’exécution des énoncés.
Source : Wikipedia
Multiversion Concurrency Control
Multiversion concurrency control (abrégé en MCC ou MVCC), est une méthode informatique de contrôle des accès concurrents fréquemment utilisée dans les systèmes de gestion de base de données et les langages de programmation concernant la gestion de la mémoire.
À cet effet, une base de données ne mettra pas en œuvre des mises à jour par écrasement des anciennes données par les nouvelles, mais plutôt en indiquant que les anciennes données sont obsolètes et en ajoutant une nouvelle « version ». Ainsi, plusieurs versions sont stockées, dont l’une seule d’entre elle est la plus récente. Cela évite en outre à la base de données d’avoir à gérer le remplissage des « trous » en mémoire ou sur le disque mais nécessite (généralement) une purge régulière des données obsolètes. Dans le cas des bases de données orientées document comme CouchDB, cela a aussi pour incidence de réécrire une version complète du document à chaque mise à jour, plutôt que de gérer des mises à jour incrémentales constituées de petits morceaux de document liés entre eux et rangés de manière non contigüe.
MVCC autorise aussi la création de prise de vue « à un instant donné ». En réalité, les transactions avec MVCC utilisent un marqueur temporel (timestamp en anglais) ou un identifiant de transaction pour déterminer l’état de la base à lire. Ce mécanisme permet d’éviter l’usage de verrous dans les transactions car les écritures peuvent être virtuellement isolées des opérations de lecture sur les anciennes versions de la base qui ont été maintenues. Ainsi, considérant une requête en lecture ayant un identifiant de transaction donné, toutes ses valeurs sont consistantes car les opérations d’écriture disposent d’un identifiant de transaction plus élevé.
En d’autres mots, MVCC permet à chaque utilisateur connecté de voir une capture de la base. Les modifications apportées ne seront pas visibles par les autres utilisateurs avant que la transaction ne soit validée (commit).
Source : Wikipedia
Architecture de Postgres
Après avoir installé et lancé Postgres voici les processus lancés par celui-ci :
1processus de postgres
2 PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
3 1 2179 2175 2175 ? -1 S 104 0:00 /usr/lib/postgresql/9.3/bin/postgres -D /var/lib/postgresql/9.3/main -c config_file=/etc/postgresql/9.3/main/postgresql.conf
4 2179 2180 2180 2180 ? -1 Ss 104 0:00 \_ postgres: logger process
5 2179 2182 2182 2182 ? -1 Ss 104 0:00 \_ postgres: checkpointer process
6 2179 2183 2183 2183 ? -1 Ss 104 0:00 \_ postgres: writer process
7 2179 2184 2184 2184 ? -1 Ss 104 0:00 \_ postgres: wal writer process
8 2179 2185 2185 2185 ? -1 Ss 104 0:00 \_ postgres: autovacuum launcher process
9 2179 2186 2186 2186 ? -1 Ss 104 0:00 \_ postgres: stats collector process
10 2179 2703 2703 2703 ? -1 Ss 104 0:00 \_ postgres: postgres postgres 192.168.1.10(60043) idle
11 2179 2704 2704 2704 ? -1 Ss 104 0:00 \_ postgres: postgres tiny 192.168.1.10(60044) idl
Pour illustrer l’auteur de ce blog m’a aimablement autorisé à utiliser son schéma. Je vous recommande la lecture de son blog celui-ci contient des articles très intéressants sur Postgres :
http://raghavt.blogspot.in/2011/04/postgresql-90-architecture.html
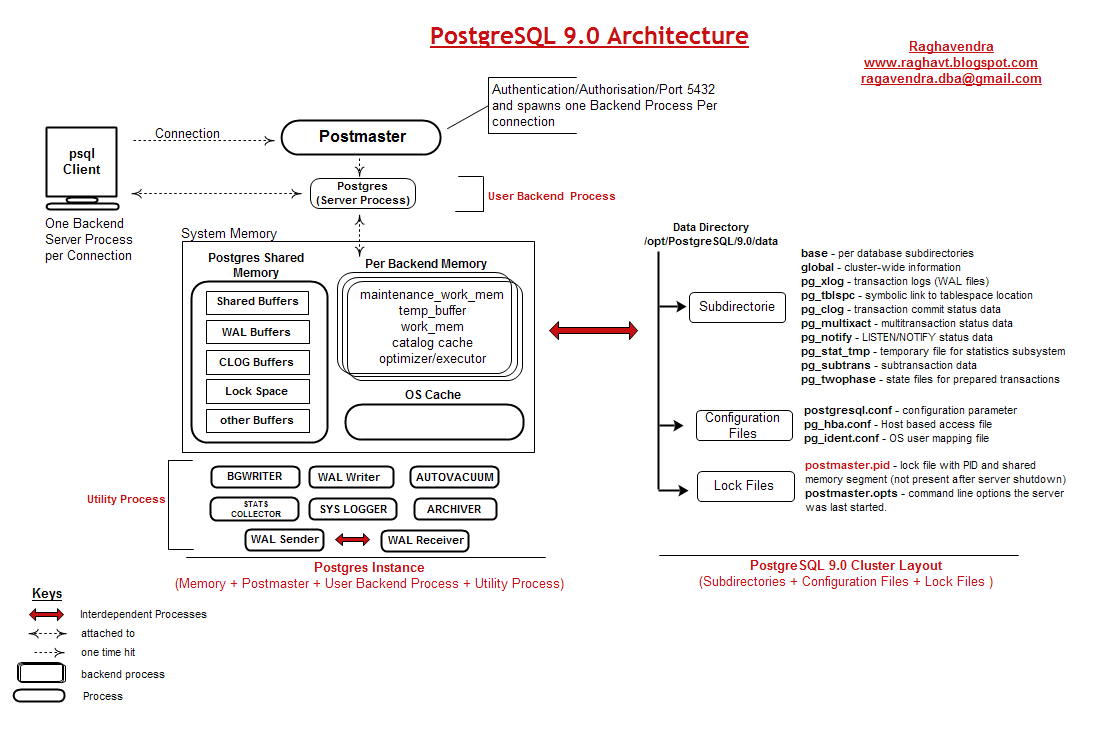
Que nous indique ce schéma?
- Il y a un process principal : Postmaster. C’est sur lui que se fait fait la connexion.
- Lors de la connexion il crée un autre processus backend qui va traiter la requête. Si votre client a tendance à initier beaucoup d’ouverture et fermeture de connexion il peut être intéressant de mettre en place un mécanisme de maintien de la connexion type pooler.
- Dans la mémoire on peut distinguer deux zones : La shared memory et per-backend memory. Comme leur nom l’indique la shared-memory sera utilisée par tous les process alors que la « per backend memory » sera dédiée à chaque processus postgres traitant une requête (backend).
- Un ensemble de processus d’arrière plan nécessaire au bon fonctionnement de postgres : bgwriter (renomé en writer depuis postgres 9.2), wal writer, autovacuum, stats collector, logger, archiver…
- Le dossier de l’instance postgres contient les fichiers de configuration (ça dépend de la distribution), les fichiers pid et lock et un ensemble de répertoires. Les plus essentiels sont :
- base : contient les fichiers de la base de donnée
- pg_xlog : Contient les journaux de transaction
- pg_stat_tmp : Contient des données temporaires nécessaire au collecteur de statistique. Les données dans ce répertoire ne sont pas utile pour la base, si on les perd ce n’est pas grave. Il est recommandé de placer cet espace sur un petit ramdisk.
- pg_log : Contient les logs de postgres
Pour approfondir sur les processus Postgres :
http://www.dalibo.org/glmf112_les_processus_de_postgresql
Principe des journaux de transaction
Afin de garantir l’atomicité d’une transaction il faut être sûr que la transaction ait bien été réalisée. Que ce soit un insert, un update, un delete … On peut simplement penser que le SGBD écrit les informations sur le disque avant d’indiquer au client que la transaction s’est bien déroulée. Comment se comporterait un tel système avec des accès concurrents ou un seul accès mais effectuant de nombreuses requêtes? Il faut se rapprocher au plus près du matériel : les disques durs. Les têtes d’enregistrement doivent se déplacer pour lire et écrire les données, s’il y a plusieurs demandes il y a une file d’attente. Pendant que le disque écrit il ne peut pas lire et inversement, les performances seraient désastreuses. Pour éviter ces files d’attentes il y a le journal de transaction. Postgres écrit d’abord les informations dans son journal (pg_xlog) avant d’indiquer au client que la requête a bien été réalisée.
L’écriture de ce journal se fait de manière séquentielle et synchrone, permettant à Postgres de supporter une charge importante de modifications des données. On comprend facilement pourquoi il est important de séparer les journaux de transaction du reste des fichiers de bases et en quoi il est important de leur consacrer un ensemble de disques dédiés (RAID 10 par exemple).
Un processus de Postgres (writer) se charge d’écrire les journaux de transactions dans la base (répertoire base). Ceci permet une rotation des journaux. Par ailleurs en cas de crash Postgres doit rejouer les journaux de transaction. Il faut savoir que les fichiers de bases de Postgres peuvent ne pas être cohérents. C’est l’association des fichiers de base et des journaux de transaction qui rend la base cohérente.Attention, je parle de cohérence et non d’intégrité. Exemple, après un crash, votre base de donnée peut être intègre (pas de corruption de données) mais démarrer à un état antérieur (si le serveur ne peut pas rejouer les journaux). Sous entendu vous avez perdu des transactions.
Le writer ne supprime pas les données en base, pour faire simple, il se contente juste d’ajouter une ligne avec un numéro de transaction. Comme un système de versionning, il garde en base tous les enregistrements même ceux qui ont été modifiés. Il existe un mécanisme de nettoyage qui va permettre de libérer l’espace utilisé par les anciennes versions des enregistrements (vacuum). Attention, c’est une explication très schématique, en réalité le système est bien plus compliqué c’est pourquoi j’ai indiqué des liens à la fin de ce paragraphe pour ceux qui veulent approfondir le sujet.
Pour résumer :
- Fichier de base de Postgres : Peuvent ne pas être cohérent, les accès ne sont pas nécessairement séquentiels (Postgres essaie privilégier les accès séquentiels), les écritures sont asynchrones.
- Journaux de transaction : Écriture séquentielle, inutiles sans les fichiers de base. Sont nécessaires pour retrouver une cohérence de la base, Postgres peut les rejouer.
Pour approfondir :
http://www.dalibo.org/glmf109_operations_de_maintenance_sous_postgresql
Shared buffers
Postgres est multi-processus et non multithread. Ses processus accèdent à une zone de mémoire partagée, dite « Shared Buffers ». Si un processus doit accéder à une donnée, il le fait depuis le shared buffer. Si la donnée n’est pas présente il va la chercher sur le disque et la place dans le cache. On voit vite l’optimisation, si deux processus doivent accéder à une donnée un seul fera la lecture, le second aura déjà l’information dans le cache. Bien entendu Postgres intègre des mécanismes de nettoyage de ce cache sinon il serait vite rempli.
Tout d’abord, si un processus a besoin d’une donnée en cache il peut la verrouiller afin d’éviter qu’un autre processus modifie le tampon. Imaginons que ce processus modifie la donnée (lors d’un update par exemple). La donnée ne sera présente que dans le cache, lors du commit la donnée sera écrite dans le journal de transaction mais la donnée présente dans les fichier de base sera toujours l’ancienne donnée. Le tampon est dit « sale » dirty ce n’est que lors de l’écriture dans les fichier de base que ce tampon redevient « propre ».
En installant l’extension pg_buffercache on peut avoir un aperçu du cache :
1CREATE EXTENSION pg_buffercache;
2SELECT * FROM pg_buffercache LIMIT 3;
3 bufferid | relfilenode | reltablespace | reldatabase | relforknumber | relblocknumber | isdirty | usagecount
4----------+-------------+---------------+-------------+---------------+----------------+---------+------------
5 1 | 229643 | 1663 | 16385 | 0 | 91 | t | 5
6 2 | 229331 | 1663 | 16385 | 0 | 17 | f | 5
7 3 | 11805 | 1663 | 12043 | 0 | 0 | t | 5
Sans rentrer dans les détails on peut voir la valeur « isdirty », certain buffer sont à true. On remarque la présence d’un compteur « usagecount ». Si des processus accèdent souvent à la même donnée il est important de la conserver en mémoire. Postgres intègre un mécanisme de nettoyage du cache où il décrémente ce compteur. Quand celui-ci arrive à zéro il peut être a nouveau affecté.
Quelque minutes plus tard :
1SELECT * FROM pg_buffercache LIMIT 3;
2 bufferid | relfilenode | reltablespace | reldatabase | relforknumber | relblocknumber | isdirty | usagecount
3----------+-------------+---------------+-------------+---------------+----------------+---------+------------
4 1 | 229643 | 1663 | 16385 | 0 | 91 | f | 5
5 2 | 229331 | 1663 | 16385 | 0 | 17 | f | 5
6 3 | 11805 | 1663 | 12043 | 0 | 0 | f | 5
On constate que tous les buffers son clean, les données ont été écrites dans les fichiers de base.
Il y a plusieurs moyens pour écrire les données en base. Le principal étant le processus writer qui se lance régulièrement pour nettoyer les buffers. Il y a aussi le checkpointer qui a intervalle régulier va vider tous les buffers dirty. Enfin, le processus en charge d’une requête peut être amené à nettoyer un buffer.
Qu’est-ce qu’il se passe lorsque le shared buffer arrive à saturation? Si un processus a besoin d’un buffer et qu’il n’y en a plus de disponible (ils sont tous sales « dirty »). Le processus en charge de la requête va déclencher les écritures sur le disque pour nettoyer les buffers. Le cout de cette opération est énorme, les écritures sur disque sont lentes d’autant plus que celles-ci se font de manière aléatoires sur le disque. Il faut éviter à tout prix cette situation.
Il existe une vue assez pratique pour voir comment sont écris les buffer : pg_stat_bgwriter :
1select * from pg_stat_bgwriter;
2 checkpoints_timed | checkpoints_req | checkpoint_write_time | checkpoint_sync_time | buffers_checkpoint | buffers_clean | maxwritten_clean | buffers_backend | buffers_backend_fsync | buffers_alloc | stats_reset
3-------------------+-----------------+-----------------------+----------------------+--------------------+---------------+------------------+-----------------+-----------------------+---------------+-------------------------------
4 11494 | 16 | 1048822079 | 2927551 | 10497060 | 0 | 0 | 88433 | 0 | 77381 | 2014-10-01 23:30:04.259356+02
Les checkpoints peuvent être déclenché à l’issue d’une timeout (checkpoint_timeout) ou « à la demande » : par la commande CHECKPOINT ou si on a atteint le nombre max de journaux de transaction entre deux checkpoint défini par le paramètre : checkpoint_segments. Si le nombre checkpoints_req augmente rapidement ça signifie qu’il y a beaucoup d’écritures, les journaux se remplissent plus vite qu’ils ne se vident du coup postgres déclenche des checkpoints.
buffers_checkpoint nous indique le nombre buffers écrit par le checkpointer, buffers_clean le nombre de buffers écrit par le processus d’écriture en arrière plan (bgwriter). Il est préférable que les buffers soient écrit par ces deux processus. Les valeurs suivantes buffers_backend et buffers_backend_fsync indiquent respectivement les buffers écrit par les processus en charge des requêtes et les écritures ayant nécessitées un fsync. Ce dernier cas est à éviter à tout prix. Ça peut arriver quand tous les buffers sont utilisés et que processus en charge d’une requête doivent forcer le vidage des buffers.
Cette zone mémoire est très importante, elle permet d’éviter les accès disques qui sont très couteux même avec le meilleur ssd du monde les accès RAM seront toujours beaucoup plus rapide.
Pour approfondir :
http://www.dalibo.org/glmf107_gestion_memoire_avec_postgresql
https://www.pgcon.org/2010/schedule/attachments/156_InOutBufferCache.pdf
http://fr.slideshare.net/selenamarie/illustrated-buffer-cache
http://docs.postgresqlfr.org/9.3/monitoring-stats.html
Vacuum
Comme expliqué au paragraphe sur les journaux de transaction, Postgres ne supprime pas les données sur le disque. Il indique juste qu’une nouvelle version de la donnée existe, les différentes versions s’accumulent et la base grossit petit à petit. il existe donc un système de nettoyage, dit vacuum. De base, le vacuum va marquer les enregistrements périmés, les emplacements pourront être libéré pour les futures écritures. Point important : Un vacuum simple ne libère pas l’espace disque, sauf si les enregistrement périmés étaient en fin de disque. Au fil du temps la base va se fragmenter sur le disque, ce qui va générer des accès aléatoires pour les têtes d’écriture.
Note : Il n’y a pas besoin de lancer manuellement le vacuum, celui-ci se déclenche automatiquement grâce à l’autovacuum. Sur certains forum on voit des sysadmin qui ne savent pas à quoi correspond ce vacuum et recommandent de le désactiver. Dans la plupart des situations il faut laisser faire postgres. L’autovacuum procède également à un ANALYZE des tables, cette opération permet à Postgres d’avoir des statistiques sur les tables et d’améliorer le fonctionnement de l’optimiseur de requêtes.
Pour remédier à la fragmentation et à « la non libération des espaces vides » il existe le vacuum full. Celui-ci va défragmenter les tables en réécrivant tous les enregistrements de manière séquentielle et effectue un reindex des tables (les données ont été déplacées sur le disque). Cette opération a un impact sur les performances mais aussi sur l’utilisation de la base : Le vacuum full va poser un verrou exclusif sur les tables au moment de la réécriture. Suivant la taille des tables ce verrou peut durer plus ou moins longtemps. Il est recommandé de lancer un vacuum full lors de taches de maintenance. Après un vacuum full on peut observer un gain sur les performances, notamment sur les accès séquentiels.
Pour approfondir
http://www.dalibo.org/glmf109_operations_de_maintenance_sous_postgresql
J’espère que cet article vous aura éclairé sur le fonctionnement de Postgres. C’est assez difficile de ne pas sacrifier le fond à la forme. J’ai essayé d’expliquer certains mécanismes sans aller trop loin dans le détails, néanmoins je vous laisse la possibilité d’approfondir vos connaissances en citant mes sources. Maintenant nous allons faire un grand saut et je vous invite à lire l’article suivant traitant de la réplication par transfert de journaux de transaction.

J’ai occupé pendant 7 ans divers postes d’ingénieur système et réseau. Et c’est à partir de 2013 que j’ai commencé à mettre les doigts dans PostgreSQL. J’ai occupé des postes de consultant, formateur, mais également DBA de production (Doctolib, Peopledoc).
Ce blog me permet de partager mes connaissances et trouvailles, ainsi que mes interventions et conférences.