Index BRIN – Fonctionnement
La version 9.5 de PostgreSQL sortie en Janvier 2016 propose un nouveau type d’index : les Index BRIN pour Bloc Range INdex. Ces derniers sont recommandés pour les tables volumineuses et corrélées avec leur emplacement. J’ai décidé de consacrer une série d’article sur ces index :
- Index BRIN - Principe
- Index BRIN - Fonctionnement
- Index BRIN - Corrélation
- Index BRIN - Performances
Pour information, je serai présent au PGDay France à Lille le mardi 31 mai pour présenter cet index. Il y aura également plein d’autres conférences intéressantes!
Dans ce 2eme volet nous allons voir en détail le fonctionnement d’un index BRIN.
Fonctionnement
L’index va contenir la valeur minimale et maximale 1 d’un attribut sur un ensemble de blocs : range (dans le cas d’un index sur une seule colonne)
La taille du range par défaut est de 128 blocs (128 x 8Ko => 1Mo).
Prenons l’exemple suivant, une table de 100 000 lignes contenant une colonne id incrémentée de 1. Schématiquement ma table sera stockée de cette façon (un bloc pouvant contenir plusieurs lignes) :
| Bloc | id |
|---|---|
| 0 | 1 |
| 0 | 2 |
| … | … |
| 1 | 227 |
| … | … |
| 128 | 28929 |
| … | … |
| 255 | 57856 |
| 256 | 57857 |
| … | … |
CREATE TABLE t1 (c1) AS (SELECT * FROM generate_series(1,100000));
SELECT ctid,c1 from t1;
Si on cherche les valeurs comprises entre 28929 et 57856 le moteur devra parcourir l’intégralité de la table. Il ne sait pas qu’il n’est pas nécessaire de lire avant le bloc 128 et après le bloc 255.
Le premier réflexe serait de créer un index b-tree. Sans rentrer dans les détails, ce type d’index permet un parcours plus efficace de la table. Il contiendra l’emplacement de chaque valeur de la table.
Schématiquement, en omettant la présentation en arborescence, l’index contiendrait :
| id | Emplacement |
|---|---|
| 1 | 0 |
| 2 | 0 |
| … | |
| 227 | 1 |
| … | … |
| 57857 | 256 |
Intuitivement on peut déjà en déduire que si notre table est volumineuse, l’index sera également volumineux.
Un index BRIN contiendrait les lignes suivantes :
| Range (128 blocs) | min | max | allnulls | hasnulls |
|---|---|---|---|---|
| 1 | 1 | 28928 | non | non |
| 2 | 28929 | 57856 | non | non |
| 3 | 57857 | 86784 | non | non |
| 4 | 86785 | 115712 | non | non |
create index ON t1 using brin(c1) ;
create extension pageinspect;
SELECT * FROM brin_page_items(get_raw_page('t1_c1_idx', 2), 't1_c1_idx');
Ainsi en cherchant les valeurs comprises entre 28929 et 57856 le moteur sait qu’il devra parcourir les blocs 128 à 255.
En comparant par rapport à un index B-tree j’ai pu représenter en 4 lignes ce qui m’aurait pris plus de 100 000 lignes dans un B-tree. Bien entendu la réalité est bien plus complexe, néanmoins, cette simplification permet déjà d’avoir un aperçu de la compacité de ce type d’index.
Influence taille du range
Par défaut la taille du range est de 128 blocs, ce qui correspond à 1Mo (1 bloc fait 8Ko). Par curiosité on va tester différentes tailles de range grâce à l’option pages_per_range.
Prenons un jeu de données plus conséquent, avec 100 millions de lignes :
CREATE TABLE brin_large (c1 INT);
INSERT INTO brin_large SELECT * FROM generate_series(1,100000000);
Notre table fait presque 3,5Go :
\dt+ brin_large
List OF relations
Schema | Name | TYPE | Owner | SIZE | Description
--------+------------+-------+----------+---------+-------------
public | brin_large | TABLE | postgres | 3458 MB |
Activons l’option « \timing » de psql afin de mesurer le temps de créations des index. Commençons par les index BRIN avec une valeur pages_per_range différente :
CREATE INDEX brin_large_brin_idx ON brin_large USING brin (c1);
CREATE INDEX brin_large_brin_idx_8 ON brin_large USING brin (c1) WITH (pages_per_range = 8);
CREATE INDEX brin_large_brin_idx_16 ON brin_large USING brin (c1) WITH (pages_per_range = 16);
CREATE INDEX brin_large_brin_idx_32 ON brin_large USING brin (c1) WITH (pages_per_range = 32);
CREATE INDEX brin_large_brin_idx_64 ON brin_large USING brin (c1) WITH (pages_per_range = 64);
Créons également un index b-tree :
CREATE INDEX brin_large_btree_idx ON brin_large USING btree (c1);
Comparons les tailles :
\di+ brin_large*
List OF relations
Schema | Name | TYPE | Owner | TABLE | SIZE | Description
--------+------------------------+-------+----------+------------+---------+-------------
public | brin_large_brin_idx | INDEX | postgres | brin_large | 128 kB |
public | brin_large_brin_idx_16 | INDEX | postgres | brin_large | 744 kB |
public | brin_large_brin_idx_32 | INDEX | postgres | brin_large | 392 kB |
public | brin_large_brin_idx_64 | INDEX | postgres | brin_large | 216 kB |
public | brin_large_brin_idx_8 | INDEX | postgres | brin_large | 1448 kB |
public | brin_large_btree_idx | INDEX | postgres | brin_large | 2142 MB |
Voici les résultats obtenus sur les durées de création des index et leur tailles :
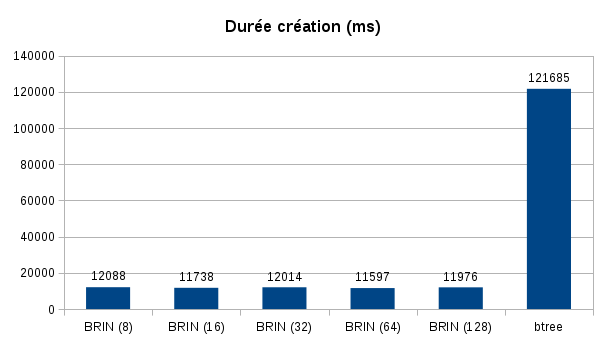
La création d’index est bien plus rapide. Il y a quasiment un facteur x10 entre les deux types d’index. J’ai obtenu ces chiffres avec la version 9.5.1 sur une configuration assez basique (pc portable et disque mécanique). Je vous conseille de mener vos propres tests avec votre matériel.
Pour information j’ai positionné la maintenance_work_mem à 1GB, malgré cette valeur élevée cela n’a pas empêché la création de fichiers temporaires pour l’index b-tree.
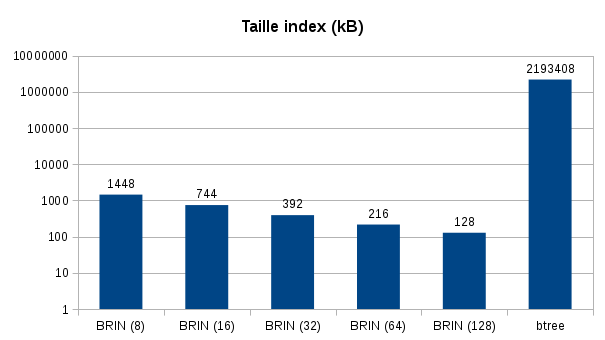
Pour les tailles d’index la différence est bien plus importante, j’ai du utiliser une échelle logarithmique pour représenter l’écart. L’index BRIN avec un pages_per_range par défaut fait 128Ko alors que le b-tree fait plus de 2Go!
Qu’en est-il des requêtes ?
Essayons cette requête qui récupère les valeurs comprises entre 10 et 2000. Pour étudier en détail ce que fait le moteur nous allons utiliser EXPLAIN avec les options (ANALYZE,VERBOSE,BUFFERS).
Enfin, pour faciliter l’analyse nous allons utiliser un jeu de données plus petit :
CREATE TABLE brin_demo (c1 INT);
INSERT INTO brin_demo SELECT * FROM generate_series(1,100000);
EXPLAIN (ANALYZE,BUFFERS,VERBOSE) SELECT c1 FROM brin_demo WHERE c1> 1 AND c1<2000;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Seq Scan on public.brin_demo (cost=0.00..2137.47 rows=565 width=4) (actual time=0.010..11.311 rows=1998 loops=1)
Output: c1
Filter: ((brin_demo.c1 > 1) AND (brin_demo.c1 < 2000))
Rows Removed by Filter: 98002
Buffers: shared hit=443
Planning time: 0.044 ms
Execution time: 11.412 ms
Sans index le moteur parcourt toute la table (seq scan) et lit 443 blocs.
La même requête avec un index BRIN :
CREATE INDEX brin_demo_brin_idx ON brin_demo USING brin (c1);
EXPLAIN (ANALYZE,BUFFERS,VERBOSE) SELECT c1 FROM brin_demo WHERE c1> 1 AND c1<2000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.brin_demo (cost=17.12..488.71 rows=500 width=4) (actual time=0.034..3.483 rows=1998 loops=1)
Output: c1
Recheck Cond: ((brin_demo.c1 > 1) AND (brin_demo.c1 < 2000))
Rows Removed by Index Recheck: 26930
Heap Blocks: lossy=128
Buffers: shared hit=130
-> Bitmap Index Scan on brin_demo_brin_idx (cost=0.00..17.00 rows=500 width=0) (actual time=0.022..0.022 rows=1280 loops=1)
Index Cond: ((brin_demo.c1 > 1) AND (brin_demo.c1 < 2000))
Buffers: shared hit=2
Planning time: 0.074 ms
Execution time: 3.623 ms
Le moteur lit 2 blocs d’index puis 128 blocs de la table.
Essayons avec un pages_per_range plus petit, à 16 par exemple :
CREATE INDEX brin_demo_brin_idx_16 ON brin_demo USING brin (c1) WITH (pages_per_range = 16);
EXPLAIN (ANALYZE,BUFFERS,VERBOSE) SELECT c1 FROM brin_demo WHERE c1> 10 AND c1<2000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.brin_demo (cost=17.12..488.71 rows=500 width=4) (actual time=0.053..0.727 rows=1989 loops=1)
Output: c1
Recheck Cond: ((brin_demo.c1 > 10) AND (brin_demo.c1 < 2000))
Rows Removed by Index Recheck: 1627
Heap Blocks: lossy=16
Buffers: shared hit=18
-> Bitmap Index Scan on brin_demo_brin_idx_16 (cost=0.00..17.00 rows=500 width=0) (actual time=0.033..0.033 rows=160 loops=1)
Index Cond: ((brin_demo.c1 > 10) AND (brin_demo.c1 < 2000))
Buffers: shared hit=2
Planning time: 0.114 ms
Execution time: 0.852 ms
La encore le moteur lit 2 blocs dans l’index, en revanche il ne va lire que 16 blocs dans la table.
Un index avec un pages_per_range plus petit sera plus sélectif et permettra de lire moins de blocs.
Utilisons l’extension pageinspect pour observer le contenu des index :
CREATE extension pageinspect;
SELECT * FROM brin_page_items(get_raw_page('brin_demo_brin_idx_16', 2),'brin_demo_brin_idx_16');
itemoffset | blknum | attnum | allnulls | hasnulls | placeholder | value
------------+--------+--------+----------+----------+-------------+-------------------
1 | 0 | 1 | f | f | f | {1 .. 3616}
2 | 16 | 1 | f | f | f | {3617 .. 7232}
3 | 32 | 1 | f | f | f | {7233 .. 10848}
4 | 48 | 1 | f | f | f | {10849 .. 14464}
5 | 64 | 1 | f | f | f | {14465 .. 18080}
6 | 80 | 1 | f | f | f | {18081 .. 21696}
7 | 96 | 1 | f | f | f | {21697 .. 25312}
8 | 112 | 1 | f | f | f | {25313 .. 28928}
9 | 128 | 1 | f | f | f | {28929 .. 32544}
10 | 144 | 1 | f | f | f | {32545 .. 36160}
11 | 160 | 1 | f | f | f | {36161 .. 39776}
12 | 176 | 1 | f | f | f | {39777 .. 43392}
13 | 192 | 1 | f | f | f | {43393 .. 47008}
14 | 208 | 1 | f | f | f | {47009 .. 50624}
15 | 224 | 1 | f | f | f | {50625 .. 54240}
16 | 240 | 1 | f | f | f | {54241 .. 57856}
17 | 256 | 1 | f | f | f | {57857 .. 61472}
18 | 272 | 1 | f | f | f | {61473 .. 65088}
19 | 288 | 1 | f | f | f | {65089 .. 68704}
20 | 304 | 1 | f | f | f | {68705 .. 72320}
21 | 320 | 1 | f | f | f | {72321 .. 75936}
22 | 336 | 1 | f | f | f | {75937 .. 79552}
23 | 352 | 1 | f | f | f | {79553 .. 83168}
24 | 368 | 1 | f | f | f | {83169 .. 86784}
25 | 384 | 1 | f | f | f | {86785 .. 90400}
26 | 400 | 1 | f | f | f | {90401 .. 94016}
27 | 416 | 1 | f | f | f | {94017 .. 97632}
28 | 432 | 1 | f | f | f | {97633 .. 100000}
(28 lignes)
SELECT * FROM brin_page_items(get_raw_page('brin_demo_brin_idx', 2),'brin_demo_brin_idx');
itemoffset | blknum | attnum | allnulls | hasnulls | placeholder | value
------------+--------+--------+----------+----------+-------------+-------------------
1 | 0 | 1 | f | f | f | {1 .. 28928}
2 | 128 | 1 | f | f | f | {28929 .. 57856}
3 | 256 | 1 | f | f | f | {57857 .. 86784}
4 | 384 | 1 | f | f | f | {86785 .. 100000}
(4 lignes)
Avec l’index brin_demo_brin_idx_16 on remarque bien que les valeurs qui nous intéressent sont présentes dans le premier ensemble de blocs (0 à 15). En revanche avec l’index brin_demo_brin_idx, celui-ci est moins sélectif. Les valeurs qui nous intéressent sont comprises les blocs 0 à 127 ce qui explique pourquoi il y a plus de blocs lus dans le premier exemple.
-
L’index contient également deux booléens indiquant si l’ensemble contient des valeurs NULL (hasnulls ) ou s’il ne contient que des valeurs NULL (allnulls) ↩︎